一、使用hashset去重
@Test
public void hashMapTest() {
long start = System.currentTimeMillis();
Set<Integer> hashset = new HashSet<>(SIZE);
for (int i = 0; i < 10000000; i++) {
hashset.add(i);
}
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start));
}
将数据全部加载到内存,这种方式在内存有限的情况会出现OOM,比如设置JVM参数:
-Xms64m -Xmx64m -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
将提示异常:
java.lang.OutOfMemoryError: Java heap space
at java.util.HashMap.resize(HashMap.java:703)
at java.util.HashMap.putVal(HashMap.java:628)
at java.util.HashMap.put(HashMap.java:611)
at java.util.HashSet.add(HashSet.java:219)
at com.jep.leetcode.TestBloomFilter.hashMapTest(TestBloomFilter.java:25)
查看GC日志:
{Heap before GC invocations=0 (full 0):
par new generation total 19648K, used 4551K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000)
eden space 17472K, 26% used [0x00000007bc000000, 0x00000007bc471e70, 0x00000007bd110000)
from space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000)
to space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000)
concurrent mark-sweep generation total 43712K, used 0K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K
class space used 495K, capacity 530K, committed 640K, reserved 1048576K
Heap after GC invocations=1 (full 1):
par new generation total 19648K, used 0K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000)
eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000)
from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000)
to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000)
concurrent mark-sweep generation total 43712K, used 959K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K
class space used 495K, capacity 530K, committed 640K, reserved 1048576K
}
{Heap before GC invocations=1 (full 1):
par new generation total 19648K, used 0K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000)
eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000)
from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000)
to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000)
concurrent mark-sweep generation total 43712K, used 959K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K
class space used 495K, capacity 530K, committed 640K, reserved 1048576K
Heap after GC invocations=2 (full 2):
par new generation total 19648K, used 0K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000)
eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000)
from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000)
to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000)
concurrent mark-sweep generation total 43712K, used 918K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K
class space used 495K, capacity 530K, committed 640K, reserved 1048576K
}
invocations=后的数字表示的是总的GC次数 full后的数字则是其中full GC的次数
二、布隆过滤器
前置知识
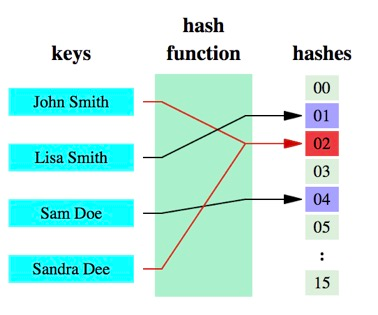
哈希函数:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。
原理介绍
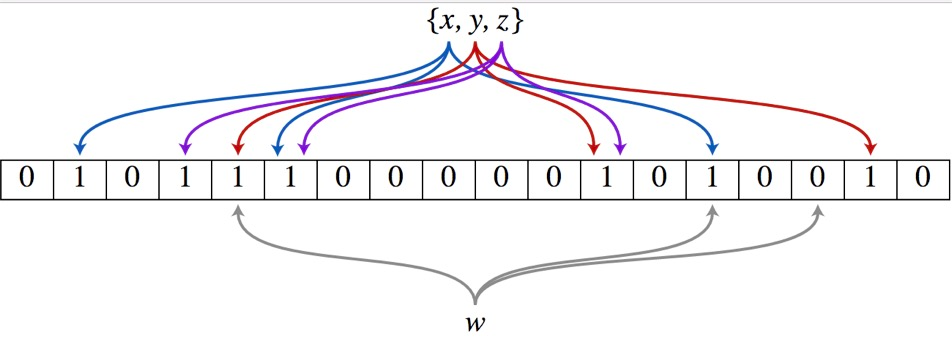 1、假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。
1、假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。
2、对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
3、查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中(即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个数据最后定位到的位置是一模一样的,这点和 HashMap 类似)。
添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
总结:基于以上的 Hash 冲突的前提,所以 Bloom Filter 有一定的误报率,这个误报率和 Hash 算法的次数 H,以及数组长度 L 都是有关的。
使用guava的布隆过滤器:
@Test
public void guavaTest() {
long star = System.currentTimeMillis();
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
10000000,
0.01);
for (int i = 0; i < 10000000; i++) {
filter.put(i);
}
Assert.assertTrue(filter.mightContain(1));
Assert.assertTrue(filter.mightContain(2));
Assert.assertTrue(filter.mightContain(3));
Assert.assertFalse(filter.mightContain(10000000));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
create方法中最关键的是最后两个参数,查看源码:
/**
* Creates a {@link BloomFilter} with the expected number of insertions and expected false
* positive probability.
*
* <p>Note that overflowing a {@code BloomFilter} with significantly more elements than specified,
* will result in its saturation, and a sharp deterioration of its false positive probability.
*
* <p>The constructed {@code BloomFilter} will be serializable if the provided {@code Funnel<T>}
* is.
*
* <p>It is recommended that the funnel be implemented as a Java enum. This has the benefit of
* ensuring proper serialization and deserialization, which is important since {@link #equals}
* also relies on object identity of funnels.
*
* @param funnel the funnel of T's that the constructed {@code BloomFilter} will use
* @param expectedInsertions the number of expected insertions to the constructed {@code
* BloomFilter}; must be positive
* @param fpp the desired false positive probability (must be positive and less than 1.0)
* @return a {@code BloomFilter}
*/
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long) expectedInsertions, fpp);
}
第二个参数代表预计要插入多少数据,第三个参数为误报率。 Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 numBits 以及需要计算几次 Hash 函数 numHashFunctions
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
提高数组长度以及 hash 计算次数可以降低误报率,但相应的 CPU、内存的消耗就会提高。 另外,数据量和数组长度差的量级太多就会导致哈希冲突激增和数组全1的情况。
执行结果
{Heap before GC invocations=103 (full 1):
par new generation total 19648K, used 17474K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000)
eden space 17472K, 100% used [0x00000007bc000000, 0x00000007bd110000, 0x00000007bd110000)
from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330810, 0x00000007bd550000)
to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000)
concurrent mark-sweep generation total 43712K, used 12408K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 4548K, capacity 5322K, committed 5504K, reserved 1056768K
class space used 530K, capacity 562K, committed 640K, reserved 1048576K
Heap after GC invocations=104 (full 1):
par new generation total 19648K, used 4K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000)
eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000)
from space 2176K, 0% used [0x00000007bd110000, 0x00000007bd111020, 0x00000007bd330000)
to space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000)
concurrent mark-sweep generation total 43712K, used 12408K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 4548K, capacity 5322K, committed 5504K, reserved 1056768K
class space used 530K, capacity 562K, committed 640K, reserved 1048576K
}
执行时间:4694
进行了103次GC,但只有一次FULL GC。




