前言
面试能考察一个人知识面的深度和广度,每一次面试都是在”照镜子”,有查漏补缺之功效。
近年来,各大公司的java面试和笔试题越来越侧重基础知识的深度,以及一些开源软件原理的理解。
本文将罗列一些java面试及笔试热点问题给大家参考,如有错误,欢迎各位看官指教。
基础篇
一、线程池是如何实现复用的?
参考ThreadPoolExecutor内部类Worker的run()方法调用:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
//取出Worker对象中的Runnable任务
Runnable task = w.firstTask;
boolean completedAbruptly = true;
...
try {
//★注意这个while循环,在这里实现了 [线程复用]
while (task != null || (task = getTask()) != null) {
//上锁
w.lock();
//检查Thread状态的代码
...
try {
...
try {
//执行Worker中的Runnable任务
task.run();
} catch (...) {
...catch各种异常
}
} finally {
//置空任务(这样下次循环开始时,task依然为null,需要再通过getTask()取) + 记录该Worker完成任务数量 + 解锁
task = null;
w.completedTasks++;
w.unlock();
}
}
//该线程已经从队列中取不到任务了,改变标记
completedAbruptly = false;
} finally {
//线程移除
processWorkerExit(w, completedAbruptly);
}
}
线程复用逻辑整理如下:
- 如果task不为空,则开始执行task
- 如果task为空,则通过getTask()再去取任务,并赋值给task,如果取到的Runnable不为空,则执行该任务
- 执行完毕后,通过while循环继续getTask()取任务
- 如果getTask()取到的任务依然是空,那么整个runWorker()方法执行完毕。
二、使用CAS实现单例。
private static final AtomicReference<Singleton> INSTANCE = new AtomicReference<Singleton>();
public static final Singleton getInstance(){
for (;;) {
Singleton current = INSTANCE.get();
if (current != null) {
return current;
}
current = new Singleton();
if (INSTANCE.compareAndSet(null, current)) {
return current;
}
}
}
三、b树和b+树的区别,数据库为什么使用b+树而不是其他二叉树?
二叉排序树组织数据时,用于查找是比较方便的,因为每次经过一次节点时,最多可以减少一半的可能,不过极端情况会出现所有节点都位于同一侧,直观上看就是一条直线,那么这种查询的效率就比较低了,因此需要对二叉树左右子树的高度进行平衡化处理,于是就有了平衡二叉树(Balenced Binary Tree)。尽可能将树变得”矮胖”。 所谓“平衡”,说的是这棵树的各个分支的高度是均匀的,它的左子树和右子树的高度之差绝对值小于1,这样就不会出现一条支路特别长的情况。于是,在这样的平衡树中进行查找时,总共比较节点的次数不超过树的高度,这就确保了查询的效率(时间复杂度为O(logn)).
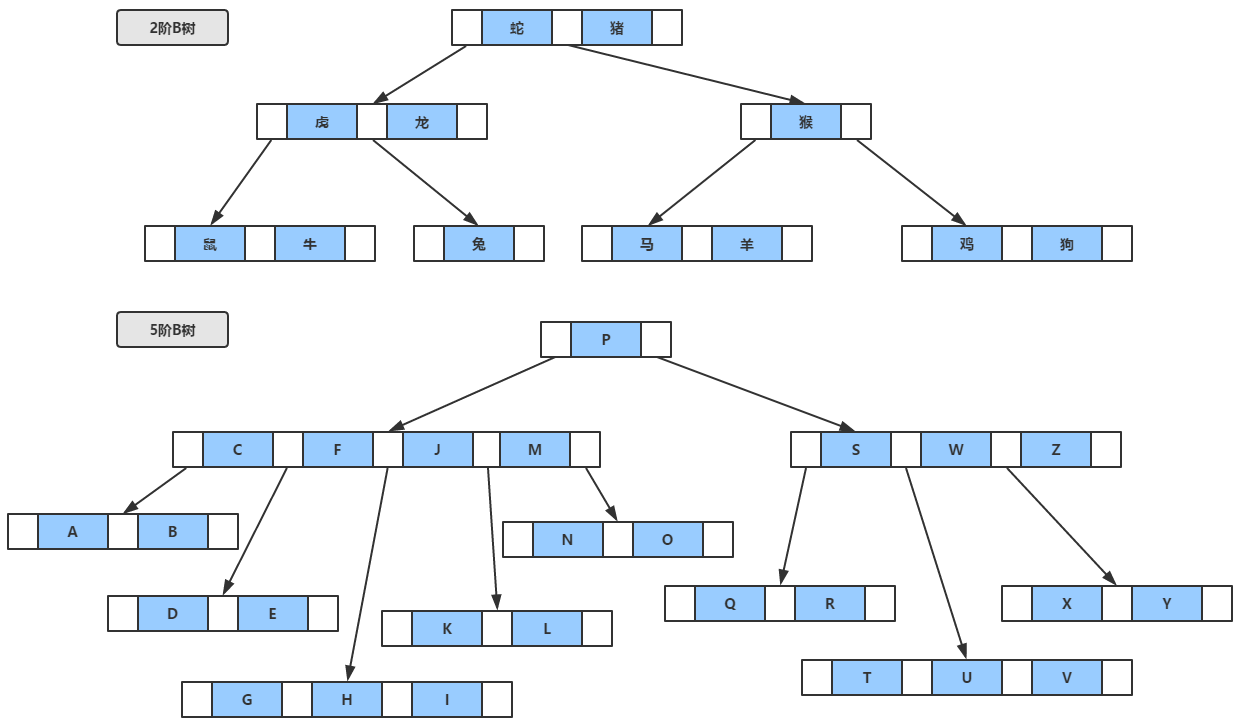
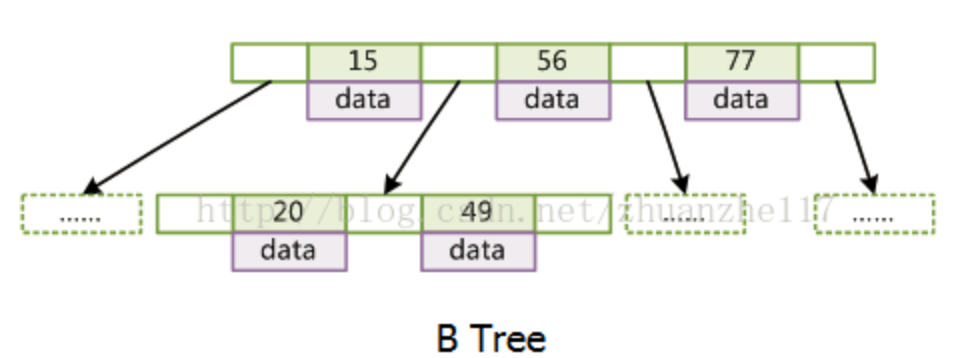
B树
每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。
B+树
只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。
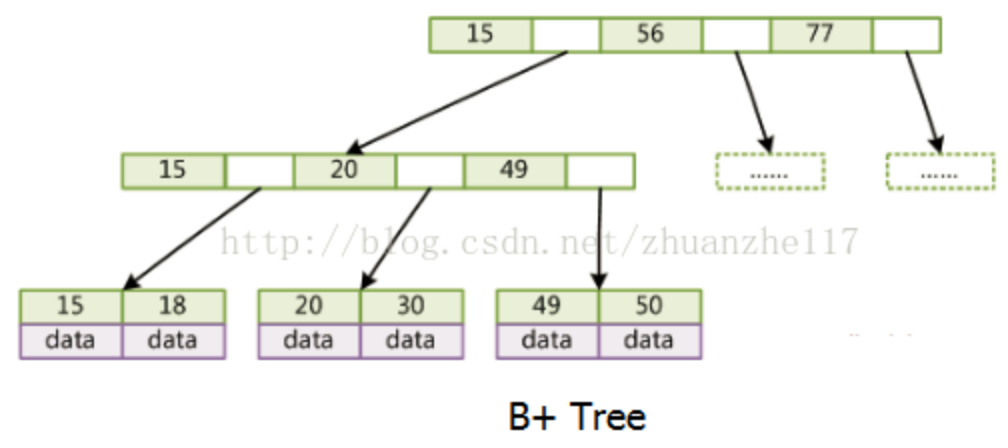
那为什么是B+树而不是B树呢,因为它内节点不存储data,这样一个节点就可以存储更多的key。
四、hashmap数据结构有什么特点,hashmap如何解决hash冲突?
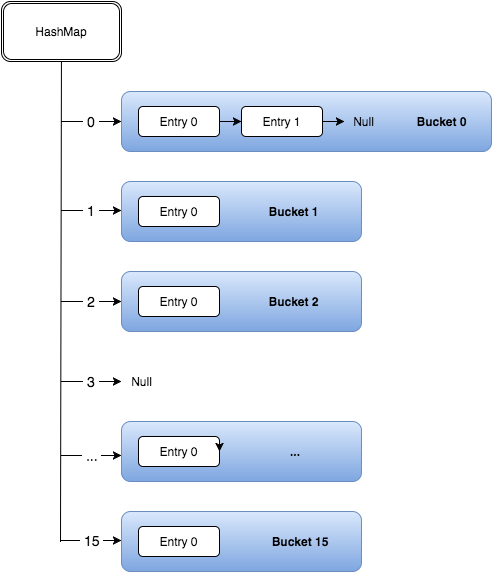
hashmap具备了数组(寻址容易,插入和删除困难)和链表(寻址困难,插入和删除容易)的优点,每一个数组中都是一个链表。 null key总是存放在Entry[]数组的第一个元素。
persons.put(“1”,”jack”); persons.put(“2”,”john”);
入股同时计算到的hash值都为123,那么jack先放在第一列的第一个位置Node-jack,persons.put(“2”,”john”); 执行时会将Node-jack的next(Node) = Node(john),Jack的下个节点将指向Node(john)。 JDK8处于提升性能的考虑,会把该链表转变成树结构。
五、使用hash一致性分片的好处
一致性hash是将数据按照特征值映射到一个首尾相接的hash环上,同时也将节点(按照IP地址或者机器名hash)映射到这个环上。 一致性hash方式在增删的时候只会影响到hash环上响应的节点,不会发生大规模的数据迁移。
六、线程的5种状态,如何互相切换
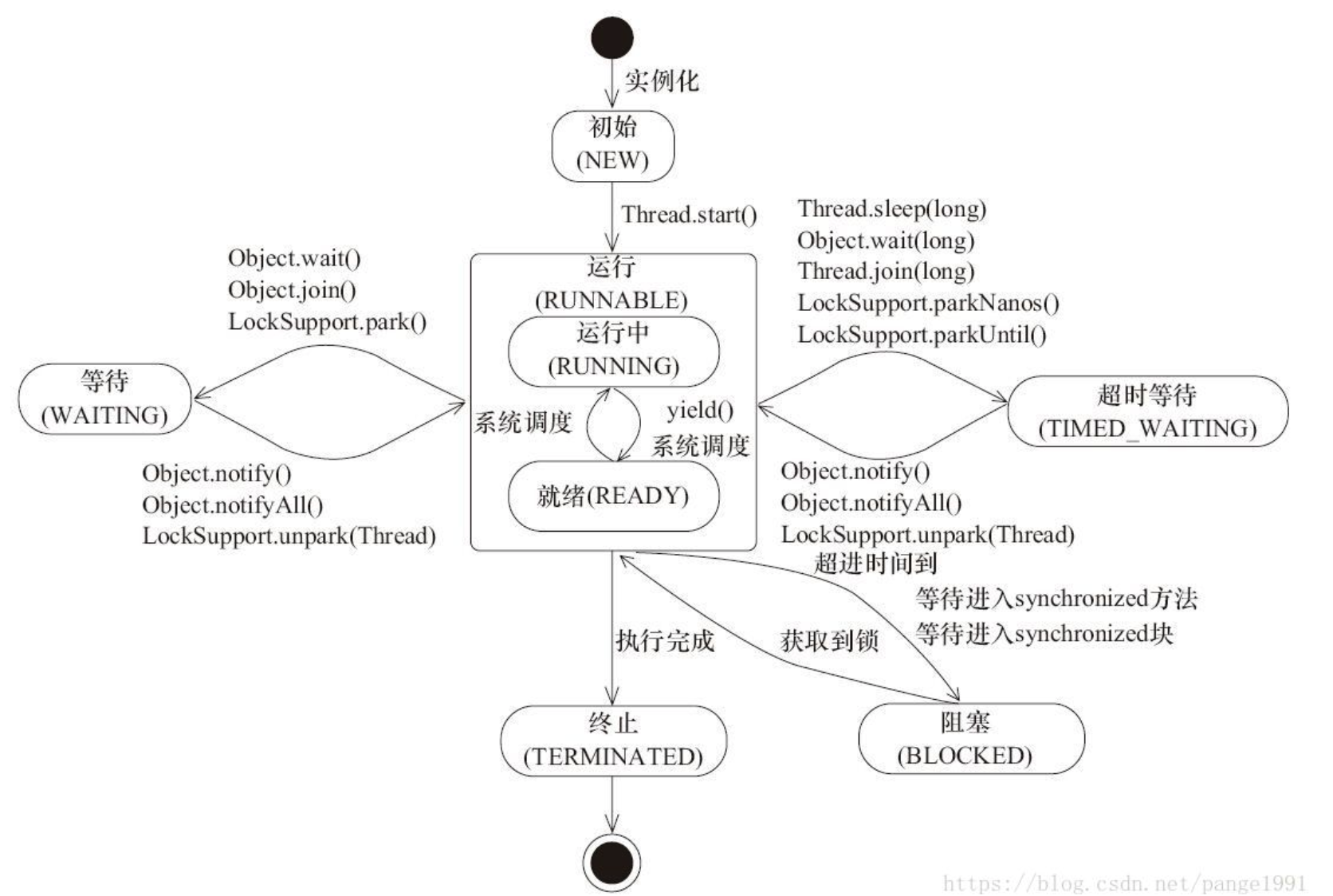
七、线程是否可以重复启动,会有什么后果? if (threadStatus != 0)/新的线程threadState值是0 throw new IllegalThreadStateException();
在每次实例化的时候,会给这个threadStatus 为0,用volatile ,可以保证该变量的可见性。在不同的生命周期,值会变,而在start方法通过判断,就可以知道执行的线程是不是一个新的线程实例。 Thread类中run()和start()方法的区别如下: run()方法: 在本线程内调用该Runnable对象的run()方法,可以重复多次调用; start()方法: 启动一个线程,调用该Runnable对象的run()方法,不能多次启动一个线程。
八、synchronized和lock的区别
- lock是一个接口,而synchronized是java的一个关键字,synchronized是内置的语言实现。
- synchronized在发生异常时候会自动释放占有的锁,因此不会出现死锁;而lock发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生。(所以最好将同步代码块用try catch包起来,finally中写入unlock,避免死锁的发生)
- lock中有个方法 void lockInterruptibly() throws InterruptedException; lock等待锁过程中可以用interrupt来中断等待,而synchronized只能等待锁的释放,不能响应中断;
- interface ReadWriteLock 读写锁可以提高多线程读操作的效率
九、jdk6之后对synchronized做了哪些优化?
Java SE1.6中,锁一共有四种状态,从低到高:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。 锁可以升级但不能降级,这种策略是为了提高获得锁和释放锁的效率。
java对象头里的mark word里默认存储对象的HashCode、分代年龄和锁标记位。

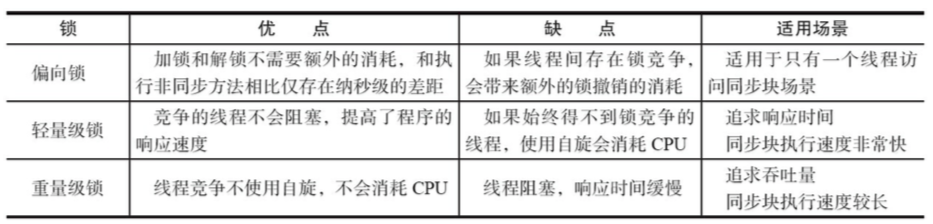 “偏向”的意思是,偏向锁假定将来只有第一个申请锁的线程会使用锁(不会有任何线程再来申请锁),因此,只需要在Mark Word中CAS记录owner(本质上也是更新,但初始值为空),如果记录成功,则偏向锁获取成功,记录锁状态为偏向锁,以后当前线程等于owner就可以零成本的直接获得锁;否则,说明有其他线程竞争,膨胀为轻量级锁。
“偏向”的意思是,偏向锁假定将来只有第一个申请锁的线程会使用锁(不会有任何线程再来申请锁),因此,只需要在Mark Word中CAS记录owner(本质上也是更新,但初始值为空),如果记录成功,则偏向锁获取成功,记录锁状态为偏向锁,以后当前线程等于owner就可以零成本的直接获得锁;否则,说明有其他线程竞争,膨胀为轻量级锁。
十、悲观锁、乐观锁,如何实现一个乐观锁
- 悲观锁:每次操作时都认为其他线程会修改,所以都会加锁,当其他线程想要访问数据时,都需要阻塞挂起。
- 乐观锁:总是认为不会产生并发问题,每次操作前总认为不会有其他线程对数据进行修改,因此不会上锁,但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS操作实现。
用juc的内置方法,参照AtomicInteger:
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
getAndIncrement 采用了CAS操作,每次从内存中读取数据然后将此数据和 +1 后的结果进行CAS操作,如果成功就返回结果,否则重试直到成功为止。
十一、spring事务的实现原理 事务的特性、事务的4种隔离级别?
原理:
Spring的事务管理机制实现的原理,就是通过这样一个动态代理对所有需要事务管理的Bean进行加载,并根据配置在invoke方法中对当前调用的 方法名进行判定,并在method.invoke方法前后为其加上合适的事务管理代码。
事务的四大特性(ACID)
-
原子性(Atomicity) 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。
-
一致性(Consistency) 一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
-
隔离性(Isolation)隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
-
持久性(Durability) 持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
十二、什么是脏读、不可重复读、幻读,数据库的四种隔离级别?
-
脏读:在一个事务处理过程里读取了另一个未提交的事务中的数据。
-
不可重复读:在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
-
幻读:幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。读提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
大多数数据库默认的事务隔离级别是Read committed,比如Sql Server , Oracle。MySQL的默认隔离级别是Repeatable read。
十三、CMS收集器的原理、清理步骤、优缺点。
1、CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
2、CMS是用于对tenured generation的回收,也就是年老代的回收,目标是尽量减少应用的暂停时间,减少full gc发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代。在启动JVM参数加上-XX:+UseConcMarkSweepGC ,这个参数表示对于老年代的回收采用CMS。CMS采用的基础算法是:标记—清除。收集结束时会产生大量空间碎片。
3、清理步骤
- 初始标记(STW initial mark) ***暂停应用
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark) *** 暂停 应用
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
4、HotSpot VM里CMS只负责并发收集年老代(而不是整个GC堆)。如果并发收集所回收到的空间赶不上分配的需求,就会回退到使用serial GC的mark-compact算法做full GC。也就是mark-sweep为主,mark-compact为备份的经典配置。但这种配置方式也埋下了隐患:使用CMS时必须非常小心的调优,尽量推迟由碎片化引致的full GC的发生。一旦发生full GC,暂停时间可能又会很长,这样原本为低延迟而选择CMS的优势就没了。
十四、强引用、软引用、弱引用
1、强引用:就是我们一般声明对象是时虚拟机生成的引用,强引用环境下,垃圾回收时需要严格判断当前对象是否被强引用,如果被强引用,则不会被垃圾回收。
2、软引用:软引用一般被做为缓存来使用。与强引用的区别是,软引用在垃圾回收时,虚拟机会根据当前系统的剩余内存来决定是否对软引用进行回收。如果剩余内存比较紧张,则虚拟机会回收软引用所引用的空间;如果剩余内存相对富裕,则不会进行回收。换句话说,虚拟机在发生OutOfMemory时,肯定是没有软引用存在的。
3、弱引用:弱引用与软引用类似,都是作为缓存来使用。但与软引用不同,弱引用在进行垃圾回收时,是一定会被回收掉的,因此其生命周期只存在于一个垃圾回收周期内。
强引用不用说,我们系统一般在使用时都是用的强引用。而“软引用”和“弱引用”比较少见。他们一般被作为缓存使用,而且一般是在内存大小比较受限的情况下做为缓存。因为如果内存足够大的话,可以直接使用强引用作为缓存即可,同时可控性更高。因而,他们常见的是被使用在桌面应用系统的缓存。
十五、常见的垃圾回收算法
按照回收策略分:
1、引用计数(Reference Counting): 比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
2、标记-清除(Mark-Sweep): 此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
3、复制(Copying): 此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
4、标记-整理 (Mark-Compact): 此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
按系统线程分:
1、串行收集:串行收集使用单线程处理所有垃圾回收工作, 因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
2、并行收集:并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
垃圾回收的起点是一些根对象(java栈, 静态变量, 寄存器…)
十六、介绍一下jmm
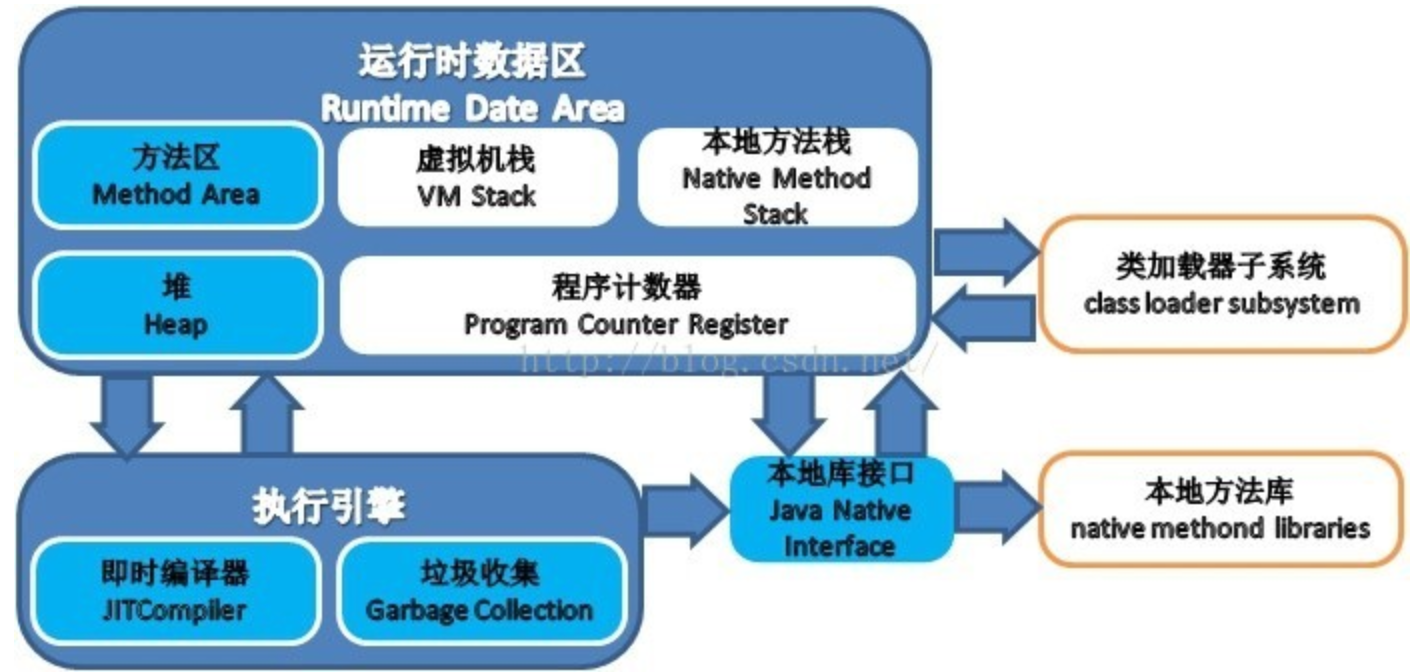
程序计数器:是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。程序中的分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器完成。由于多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,故该区域为线程私有的内存。
虚拟机栈:描述的是Java方法执行的内存模型,用于存储局部变量表、操作数栈、动态链接、方法出口等。
堆:是Java虚拟机所管理的内存中最大的一块,Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建
方法区:用于存放已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。
十七、介绍一下G1收集器
1.并发与并行:G1能充分利用多CPU、多核环境下的硬件优势,使用多个CPU(CPU或CPU核心)来缩短停顿(Stop The World)时间。
2.分代收集:G1不需要与其他收集器配合就能独立管理整个GC堆,但他能够采用不同方式去处理新建对象和已经存活了一段时间、熬过多次GC的老年代对象以获取更好收集效果。
3.空间整合:从整体来看是基于“标记-整理”算法实现,从局部(两个Region之间)来看是基于“复制”算法实现的,但是都意味着G1运行期间不会产生内存碎片空间,更健康,遇到大对象时,不会因为没有连续空间而进行下一次GC,甚至一次Full GC。
4.可预测的停顿:降低停顿是G1和CMS共同关注点,但G1除了追求低停顿,还能建立可预测的停顿模型,可以明确地指定在一个长度为M的时间片内,消耗在垃圾收集的时间不超过N毫秒
5.跨代特性:之前的收集器进行收集的范围都是整个新生代或老年代,而G1扩展到整个Java堆(包括新生代,老年代)。
如果应用追求低停顿,G1可选择,如果追求吞吐量,和Parallel Scavenge/Parallel Old组合相比G1并没有特别的优势。
十八、如何安全停止线程?
1、使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
public class IndexProcessor implements Runnable {
private static final Logger LOGGER = LoggerFactory.getLogger(IndexProcessor.class);
private volatile boolean running = true;
public void terminate() {
running = false;
}
@Override
public void run() {
while (running) {
try {
LOGGER.debug("Sleeping...");
Thread.sleep((long) 15000);
LOGGER.debug("Processing");
} catch (InterruptedException e) {
LOGGER.error("Exception", e);
running = false;
}
}
}
}
2、使用interrupt方法。第一种方法,有时需要等待处理完成再判断标志位,如果不希望出现此类情况,可以通过判断线程的状态中断线程。
和线程中断相关的方法:
- java.lang.Thread#interrupt() //中断线程
- java.lang.Thread#isInterrupted() //判断是否被中断
- public static boolean interrupted() //判断是否被中断,并清除当前中断状态
public class InterruptAndStopThread {
public static void main(String args[]) throws InterruptedException {
Thread thread = new Thread() {
@Override
public void run() {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("收到中断信号,停止该线程!");
break;
}
try {
Thread.sleep(600);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();//sleep方法由于中断抛出异常,此时,它会清除中断标记,需要重置中断标记位
}
System.out.println("Running!");
Thread.yield();
}
}
};
thread.start();
Thread.sleep(2000);
thread.interrupt();//进行中断操作
}
}
十九、volatile的用法
volatile关键字保证了在多线程环境下,被修饰的变量在别修改后会马上同步到主存,这样该线程对这个变量的修改就是对所有其他线程可见的,其他线程能够马上读到这个修改后值. 解决i++或者++i这样的线程同步问题需要使用synchronized或者AtomicXX系列的包装类,使用volatile无法得到预期的结果。
用法见十八题。
二十、什么是ThreadLocal,原理、用法,是否存在内存泄露,怎么解决。
Thread中的成员变量:ThreadLocal.ThreadLocalMap threadLocals = null;
设置到ThreadLocal中的数据,也正是写入了threadLocals(类似于weakHashmap)。其中key为ThreadLocal当前对象,value就是我们要的值。 线程退出时,Thread类会进行一些清理工作。如果我们使用线程池,那就意味着当前线程未必会退出,将一些对象设置到ThreadLocal中可能会出现内存泄露。 如果希望及时回收对象,可以使用ThreadLocal.remove方法将变量移除 ThreadLocalMap是使用 ThreadLocal的弱引用作为 Key 的,弱引用的对象在 GC 时会被回收。这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
其实,ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。 但是这些被动的预防措施并不能保证不会内存泄漏: 使用static的ThreadLocal,延长了ThreadLocal的生命周期,可能导致的内存泄漏。 分配使用了ThreadLocal又不再调用get(),set(),remove()方法,那么就会导致内存泄漏。
二十一、CAS实现原子操作有哪些问题?怎么解决?
CAS实现原子操作的三大问题:
1、ABA问题。
一个值原来是A,变成了B,又变成了A。CAS检查时会发现值没有变,其实已经变化了。
解决思路就是加版本号,每次变量更新版本号加一:1A-2B-3A
AtomicStampedReference可以解决ABA问题,当AtomicStampedReference对应的数值被修改时,除了更新数据本身外,还必须要更新时间戳。当AtomicStampedReference设置对象值时,对象值以及时间戳都必须满足期望值,写入才会成功。因此,即使对象值被反复读写,写回原值,只要时间戳发生变化,就能防止不恰当的写入。
AtomicStampedReference的几个API在AtomicReference的基础上新增了有关时间戳的信息:
//比较设置 参数依次为:期望值 写入新值 期望时间戳 新时间戳
public boolean compareAndSet(V expectedReference,V
newReference,int expectedStamp,int newStamp)
//获得当前对象引用
public V getReference()
//获得当前时间戳
public int getStamp()
//设置当前对象引用和时间戳
public void set(V newReference, int newStamp)
2、循环时长开销大。 CAS长时间不成功,会给CPU带来非常大的执行开销。
3、只能保证一个共享变量的原子操作。 对一个共享变量执行操作,可以用循环CAS的方式保证原子操作。 但对多个共享变量操作时,CAS无法保证原子性,这个时候可以用锁。还有一个取巧的方法,把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS操作ij。AtomicReference来保证引用对象间的原子性,也可以把多个变量放在一个对象里进行CAS操作。
锁机制保证了只有获得锁才能操作锁定的内存区域。除了偏向锁,JVM实现锁的方式都是使用循环CAS,即当一个线程想进入同步块时使用循环CAS的方式获取锁,退出同步块时使用循环CAS释放锁。
二十二、为什么使用线程池,线程池的处理流程?
使用线程池的好处:
- 降低资源消耗。通过重复利用已经创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。无限制地创建线程,会消耗系统资源,降低系统稳定性。
- 使用线程池可以进行统一分配、调优和监控。
ThreadPoolExecutor执行execute方法分下面四种情况:
1、如果当前运行的线程少于corePoolSize,则创建新线程执行任务(注意这一步要获取全局锁)。
2、如果运行的线程等于或多余corePoolSize,则将任务加入BlockingQueue。
3、如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(注意这一步要获取全局锁)。
4、如果创建新线程时当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用 RejectedExecutionHandler.rejectedExecution方法。
采取上述的设计,是为了在执行execute方法时,尽可能地避免获取全局锁(那将会是一个严重的伸缩瓶颈),在ThreadPoolExecutor完成预热后(当前运行的线程数大于等于corePoolSize),几乎所有的execute方法调用都是执行步骤2,步骤2不需要全局锁。
工作线程:线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务后,还会循环获取工作队列里的任务来执行。
二十三、如何合理的配置线程池
1、CPU密集型任务应配置尽可能小的线程,如配置N(CPU)+1个线程的的线程池,由于IO密集型任务线程并不一直在执行任务,则应该配置尽可能多的线程,如2*N(CPU)。
2、混合型任务,如果可拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要两个任务执行时间相差不大,则分解后执行的吞吐量将高于串行执行的吞吐量。如果两个任务执行时间相差很大,则没必要进行分解。
3、依赖数据库连接池的任务,因为线程提交sql后需要等待数据库的返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好利用CPU。
4、建议使用有界队列。有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千。 如果sql执行缓慢,则工作线程全部阻塞,任务积压在线程池里。如果设置成无界队列,则线程池的队列就会越来越多,有可能撑满内存,导致系统不可用。
二十四、CPU使用率100%怎么排查
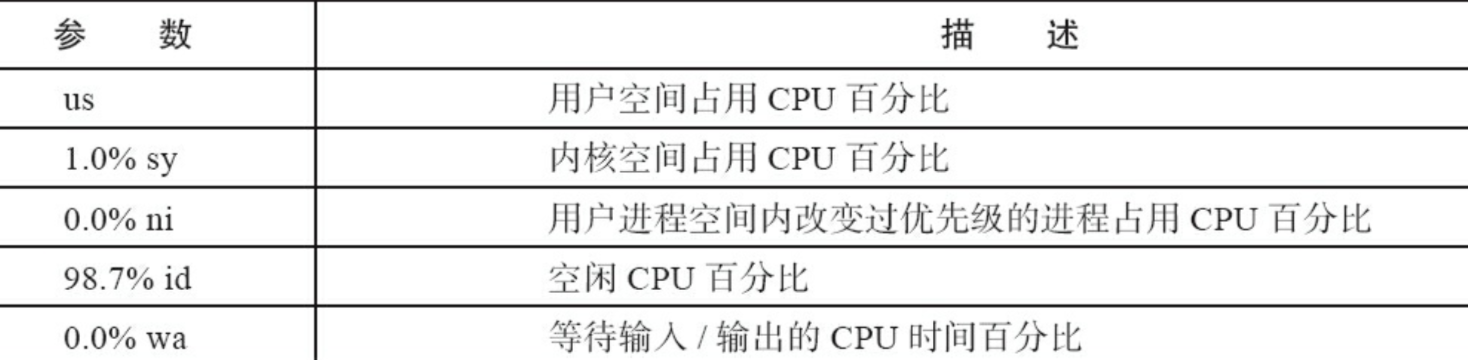
1)在linux命令下使用TOP命令查看每个进程的情况

这里的CPU利用率是300%,这个是当前所有核加在一起的CPU利用率。
2)再使用top的交互命令数字1查看每个CPU的性能数据

命令行显示到了CPU4,说明这是一个5核的虚拟机,平均每个CPU利用率在60%,如果显示100%可能有死循环。
3)使用top的交互命令H查看每个线程的性能信息。
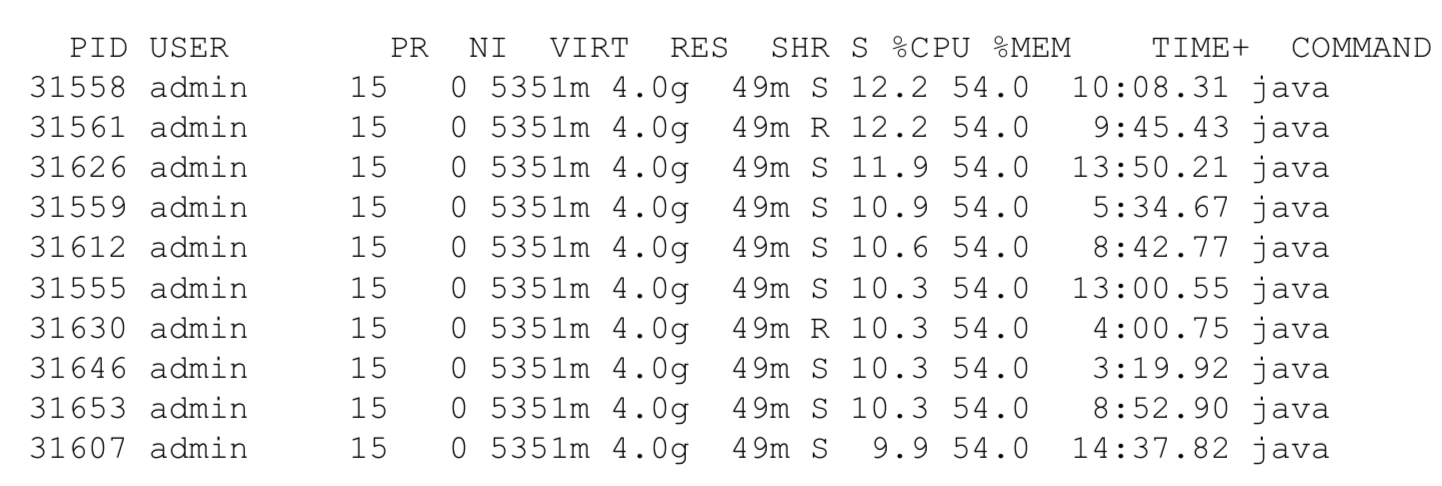
可能有三种情况:
1、某个线程CPU利用率一直100%,则说明有可能存在死循环,那么请记住这个PID。 2、某个线程一直在top10,说明该线程可能有性能问题。 3、CPU利用率高的几个线程在不停变化,说明不是由某一个线程导致CPU偏高。
如果是第一种,可能是GC造成,可以用jstat命令看一下GC情况,看看是不是因为持久带或者年老代满了,产生FULL GC,导致CPU利用率飙高。 sudo /opt/java/bin/jstat -gcutil 31177 1000 5 还可以将线程dump下来,看看究竟是哪个线程、执行什么代码造成的CPU利用率高。 sudo -u admin /opt/taobao/java/bin/jstack 31177 > /xx/xx/xx/dump dump出来的线程id是十六进制的,而我们通过top看到的线程id是十进制的,所以转换一下进制,然后用十六进制的id去dump里找对应的线程。 printf “%x\n” 31558
架构篇
一、CAP定理与设计,举例说明。
在分布式环境下,三者不可能同时满足:
1、一致性(Consistency) “all nodes see the same data at the same time”,即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性。一致性的问题在并发系统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
2、可用性(Availabilty) 可用性指”Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
3、分区容忍性(Tolerance of network Partition) 即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。 分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
用分布式系统的CAP原则来分析Zookeeper(CP):
C: Zookeeper保证了最终一致性,在十几秒可以Sync到各个节点.
A: Zookeeper保证了可用性,数据总是可用的,没有锁.并且有一大半的节点所拥有的数据是最新的,实时的. 如果想保证取得是数据一定是最新的,需要手工调用Sync()
P: 有2点需要分析的:
①节点多了会导致写数据延时非常大,因为需要多个节点同步。
② 节点多了Leader选举非常耗时, 就会放大网络的问题。
二、讲一个分布式计算的框架及结构
storm的体系结构:
Nimbus
- 集群管理 slave都向zookeeper写信息, 然后nimbus从zookeeper中获取这些slave的节点信息,那么nimbus就直到集群中有多少个节点,节点处于什么样的状态,都运行什么样的任务。
- 调度topology 当一个topology通过接口提交到集群上,nimbus负责将里面的Worker分配到supervisor上面执行。
supervisor
- 启停Worker,每台机器都会起一个supervisor进程。
- supervisor就是slave。
Worker
- 一个JVM进程资源分配的单位
- 启动executor
Executor
- 实际干活的线程
算法篇
一、2个超大字符串由数字组成,将他们求和
有数值越界的情况,需要拆分求和:
/**
* @author jep
* @version $Id: BigNumberSum.java, v 0.1 2018年07月23日 下午9:03 jep Exp $
* 整体步骤:
* 将两个字符串长度补全,补成一致长度,长度短的左边补0;
* 定义一个新的整形数组,长度为字符串的长度+1,因为结果的长度可能超出原字符串的长度(整形数组值默认为0);
* 倒序循环相加,将结果%10的余位放在低位,结果的/10的结果放在高位;最终合并结果返回。
*/
public class BigNumberSum {
public static String bigNumberPlus(String a, String b) {
int lenA = a.length();
int lenB = b.length();
if(lenA > lenB) {
b = StringUtils.leftPad(b, lenA, "0");
} else {
a = StringUtils.leftPad(a, lenB, "0");
}
int[] arrC = new int[a.length() + 1];
for(int i = a.length()-1; i>=0; i--) {
int ai = Integer.parseInt(a.charAt(i) + "" );
int bi = Integer.parseInt(b.charAt(i) + "" );
int ci = arrC[i+1];
int t = ai + bi + ci;
arrC[i+1] = t%10;
arrC[i] = t/10;
}
StringBuffer res = new StringBuffer();
for(int i = 0; i<arrC.length; i++) {
if(i==0 && arrC[i]==0) continue;
res.append(arrC[i]);
}
return res.toString();
}
public static void main(String[] args){
String a = Integer.MAX_VALUE+"";
String b = Integer.MAX_VALUE+"";
System.out.println(bigNumberPlus(a,b));//4294967294
}
}
二、什么是LRU算法
LRU(least recently used)是将近期最不会访问的数据给淘汰掉,最常见的实现是使用一个链表保存缓存数据。
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
三、一次循环查找出字符串中的第一个不重复的字符
public int getPosition(String str) {
int position = -1;
int len = str.length();
for (int i = 0; i < len; i++) {
char c1 = str.charAt(i);
if ((str.indexOf(c1)) == (str.lastIndexOf(c1))) {//第一次和最后一次位置相同
position = i;//找到
break;
}
}
return position;
}
开源软件
一、对zookeeper的认识。
zk是分布式应用程序协调服务。
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
二、hbase为什么速度快,数据是怎么存储的?
HBase的写入速度快是因为它其实并不是真的立即写入文件中,而是先写入内存,随后异步刷入HFile。
查询分为两种:
-
从内存中查询
一般响应时间在1秒内。HBase的机制是数据先写入到内存中,当数据量达到一定的量(如128M),再写入磁盘中, 在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
-
从磁盘中读取数据:
hbase是可划分成多个region,你可以简单的理解为关系型数据库的多个分区。
键是排好序了的
按列存储的
hbase的存储
一个Region代表的是一张 Hbase表中特定Rowkey范围内的数据, 而Hbase是面向列存储的数据库,所以在一个Region中,有多个文件来存储这些列。 Hbase中数据列是由列簇来组织的,所以每一个列簇都会有对应的一个数据结构,Hbase将列簇的存储数据结构抽象为Store,一个Store代表一个列簇,Store中形成很多个小的StoreFile。
三、LSM树原理
Log-Structured Merge Tree
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。 通过批量存储技术规避磁盘随机写入问题。当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。




