一、Linux命令
grep
参数说明
-R, -r, –recursive Recursively search subdirectories listed
-n, –line-number
-A num, –after-context=num
-B num, –before-context=num
-C[num, –context=num]
grep xx 1.log 2.log #多文件查询
grep 'xx' /home/admin -r -n #目录下查找所有符合关键字的文件
grep 'xx' /home/admin -r -n --include *.{vm,java} #指定文件后缀
grep 'xx' /home/admin -r -n --exclude *.{vm,java} #反匹配
seq 10 | grep 5 -A 3 #上匹配 -A表示after
seq 10 | grep 5 -B 3 #下匹配 -B表示before
seq 10 | grep 5 -C 3 #上下匹配
grep -F 的使用技巧
举例子,当我们这条命令会导致cpu很高,主要是有个“.” ,被grep认为是正则表达式
grep "xx.xx" xx.log
加上-F参数可以避免
-F fixed-string,看成一个字符串
grep "xx.xx" xx.log -F
所以在grep的时候,字符串有个.要注意,可以加grep -F 避免。
tail
tail -10f 1.log #倒数10行并进入实时监听文件写入模式
awk
内建变量
NR:NR表示从awk开始执行后,按照记录分隔符读取的数据次数,默认的记录分隔符为换行符,因此默认的就是读取的数据行数,NR可以理解为Number of Record的缩写。
FNR:在awk处理多个输入文件的时候,在处理完第一个文件后,NR并不会从1开始,而是继续累加,因此就出现了FNR,每当处理一个新文件的时候,FNR就从1开始计数,FNR可以理解为File Number of Record。
NF: NF表示目前的记录被分割的字段的数目,NF可以理解为Number of Field。
awk '{print $0}' test.txt #打印文件的全部内容(其中的$0就表示整个文件的内容)。
name grade score id
hover 2 96 2003073
twq 3 91 2003074
zsm 4 92 2003075
hzm 5 95 2003076
bl 6 96 2003077
dk : 7 : 97 : 2003078
awk '{print $1}' test.txt #抽取文件test中的第一列(如果awk没有使用-F指定分隔符号,默认的分隔符号是空格和TAB键)。
name
hover
twq
zsm
hzm
bl
awk -F: '{print $1,$2,$3,$4}' test.txt #(按照新的分隔符":"进行操作)
name grade score id
hover 2 96 2003073
twq 3 91 2003074
zsm 4 92 2003075
hzm 5 95 2003076
bl 6 96 2003077
dk 7 97 2003078
awk 'NF-=2' test.txt #不输出后面两个字段。NF是一个awk的内建变量,代表是每行的字段数量。
name grade
hover 2
twq 3
zsm 4
hzm 5
bl 6
dk : 7 : 97
awk '{for(i=3;i<NF;i++)printf("%s ",$i);print $NF}' test.txt #从第三行开始输出,%s是格式替换符,代表字符串
score id
96 2003073
91 2003074
92 2003075
95 2003076
96 2003077
7 : 97 : 2003078
awk '{print FNR,$0}' test.txt test.txt
1 name grade score id
2 hover 2 96 2003073
3 twq 3 91 2003074
4 zsm 4 92 2003075
5 hzm 5 95 2003076
6 bl 6 96 2003077
7 dk : 7 : 97 : 2003078
1 name grade score id
2 hover 2 96 2003073
3 twq 3 91 2003074
4 zsm 4 92 2003075
5 hzm 5 95 2003076
6 bl 6 96 2003077
7 dk : 7 : 97 : 2003078
awk '{print NR,$0}' test.txt test.txt
1 name grade score id
2 hover 2 96 2003073
3 twq 3 91 2003074
4 zsm 4 92 2003075
5 hzm 5 95 2003076
6 bl 6 96 2003077
7 dk : 7 : 97 : 2003078
8 name grade score id
9 hover 2 96 2003073
10 twq 3 91 2003074
11 zsm 4 92 2003075
12 hzm 5 95 2003076
13 bl 6 96 2003077
14 dk : 7 : 97 : 2003078
awk '/hover/ {print}' test.txt #匹配hover
hover 2 96 2003073
awk '!/hover/ {print}' test.txt #不匹配hover
name grade score id
twq 3 91 2003074
zsm 4 92 2003075
hzm 5 95 2003076
bl 6 96 2003077
dk : 7 : 97 : 2003078
find
find /home/admin -size +250000k #超过250000k的文件,当然+改成-就是小于了
find /home/admin f -perm 777 -exec ls -l {} \; #按照权限查询文件
find /home/admin -atime -1 #1天内访问过的文件
find /home/admin -ctime -1 #1天内状态改变过的文件
find /home/admin -mtime -1 #1天内修改过的文件
find /home/admin -amin -1 #1分钟内访问过的文件
find /home/admin -cmin -1 #1分钟内状态改变过的文件
find /home/admin -mmin -1 #1分钟内修改过的文件
find /home/admin /tmp /usr -name \*.log #多个目录去找
find . -iname \*.txt #大小写都匹配
find . -type d #当前目录下的所有子目录
netstat
netstat -nat|awk '{print $6}'|sort|uniq -c|sort -rn #查看当前连接,注意close_wait偏高的情况
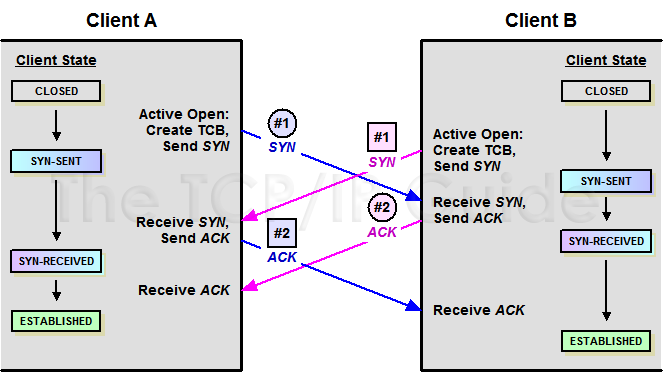
具体可参考TCP关闭连接的图:
dmesg
sudo dmesg|grep -i kill|less
找关键字oom_killer
二、jdk工具
jps
Java Virtual Machine Process Status Tool 在jdk的JAVA_HOME/bin/目录下面,jps也不例外,他就在bin目录下,所以,他是java自带的一个命令。
jstack
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 参考:http://www.importnew.com/18176.html
jinfo
查看系统启动的参数。
jmap
主要用于打印指定Java进程(或核心文件、远程调试服务器)的共享对象内存映射或堆内存细节。 具体参考:http://www.importnew.com/18196.html
jstat(JVM Statistics Monitoring Tool)
用于监控虚拟机各种运行状态信息的命令行工具. 具体参考: http://www.importnew.com/18202.html
jdb
具体参考: http://docs.oracle.com/javase/7/docs/technotes/tools/windows/jdb.html
CHLSDB
参考 http://rednaxelafx.iteye.com/blog/1847971
三、排查利器
btrace
具体参考 https://github.com/btraceio/btrace
javOSize
去官网下载javOSize的jar包。 http://s3.amazonaws.com/javosize/javosize-1.1.3.jar
ps -ef | grep java
拿到java进程号,之后将该文件copy到linux系统上,执行如下命令:
sudo -u admin java -jar javosize-1.1.3.jar PID
如果执行顺利:
$sudo -u admin java -jar javosize-1.1.3.jar 24539
Welcome to javOSize v.1.1.3 :)
We are committed to make this the best tool for you. Please, send us feedback or bugs to info@javosize.com. Thanks!!
Agent has been injected in PID 24539
[javOSize@JVM /]~> ls
apps
appthreads
breakpoints
classes
custommetrics
interceptor
jmx
memory
perfcounter
problems
repository
scheduler
sessions
sh
threads
users
classes
可以直接打开classes对class文件进行修改,比如加入日志,而不用重启服务器(v.1.1.3需要在jdk7下进行)。
cd classes
vi xxx.xxx.class
threads
ls后会出现一个列表如下:

如果想更详细的看某个线程,使用cat命令就可以。
memory
[javOSize@JVM /]~> cd memory
[javOSize@JVM /memory]~> ls
* JVM Memory (Non-HEAP) (MB)
Max: 304
In Use: 140
Free: 164
* JVM Memory (HEAP) (MB)
Max: 1148
In Use: 395
Free: 753
* OS RAM (MB)
Total: 2005
In Use: 1986
Free: 19
* SWAP (MB)
Total: 0
In Use: 0
Free: 0
* GC
Used time(%): 0.02
problems
[javOSize@JVM /]~> cd problems
[javOSize@JVM /problems]~> ls
* Concurrency
Deadlocked: false
* Memory
High GC (>2%): false
更多细节参考 http://www.javosize.com/
其他
maven helper
分析maven依赖。
VM options
类从哪里加载 -XX:+TraceClassLoading 输出dump文件 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/admin/logs/java.hprof
jar包冲突
打出所有依赖 mvn dependency:tree > ~/dependency.txt
只打出指定groupId和artifactId的依赖关系 mvn dependency:tree -Dverbose -Dincludes=groupId:artifactId
RateLimiter(精细的控制QPS)
参考:http://ifeve.com/guava-ratelimiter/




