Welcome
恩来小平的自说自话-
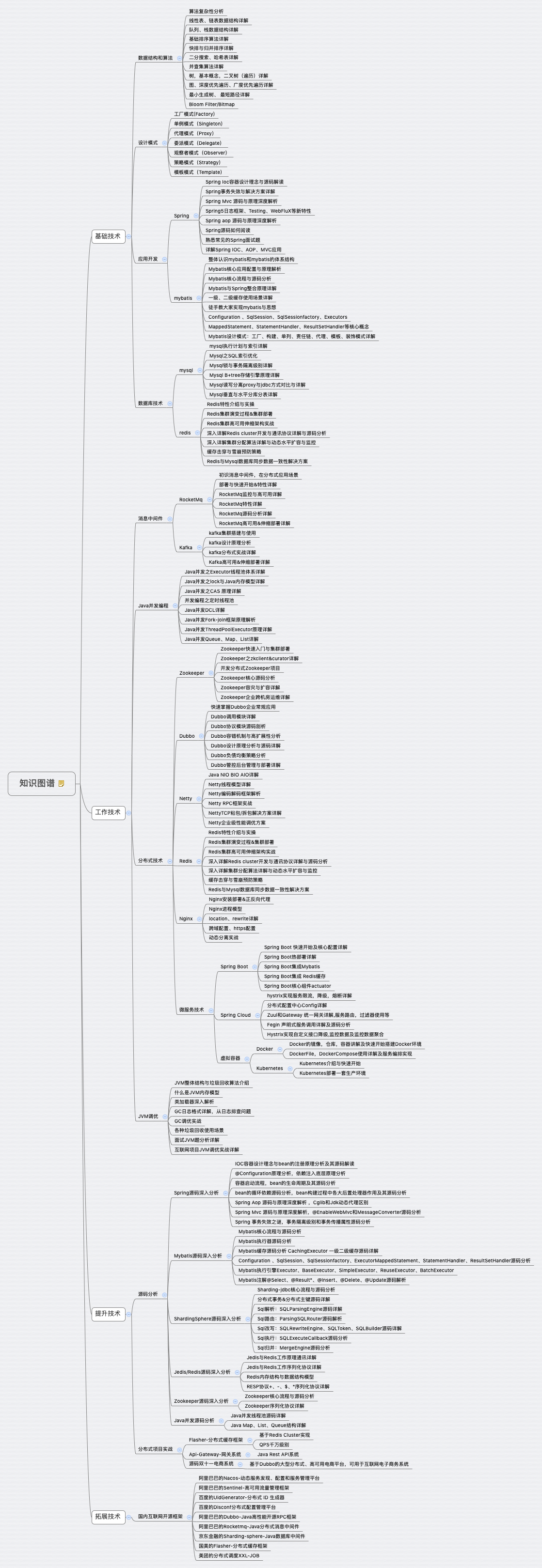
java知识图谱
-
redis的过期策略都有哪些?内存淘汰机制都有哪些?LRU代码实现?
redis删除key的策略
定期删除
所谓定期删除,指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。
惰性删除
在获取某个key的时候,如果过期了此时就会删除,不会返回任何东西。
通过上述两种手段结合起来,保证过期的key一定会被干掉。
如果定期删除漏掉了很多过期key,然后也没及时去查,也就没走惰性删除。如果大量过期key堆积在内存里,可能导致redis内存块耗尽,此时会触发内存淘汰机制。
内存淘汰策略
如果redis的内存占用过多的时候,此时会进行内存淘汰,有如下一些策略:
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
lrucache
public class LRUCache<K, V> extends LinkedHashMap<K, V> { private final int CACHE_SIZE; // 这里就是传递进来最多能缓存多少数据 public LRUCache(int cacheSize) { super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true); // 这块就是设置一个hashmap的初始大小,同时最后一个true指的是让linkedhashmap按照访问顺序来进行排序,最近访问的放在头,最老访问的就在尾 CACHE_SIZE = cacheSize; } @Override protected boolean removeEldestEntry(Map.Entry eldest) { return size() > CACHE_SIZE; // 这个意思就是说当map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据 }
-
redis都有哪些数据类型?分别在哪些场景下使用比较合适?
(1) string
这是最基本的类型了,就是普通的set和get,做简单的kv缓存。
SET key value 设置指定 key 的值 GET key 获取指定 key 的值 SETNX key value 只有在 key 不存在时设置 key 的值。(2)hash
这个是类似map的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在redis里,然后每次读写缓存的时候,可以就操作hash里的某个字段。 Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象。 Redis 中每个 hash 可以存储
2^{32}键值对(40多亿)。
HMSET key field1 value1 [field2 value2 ] 同时将多个 field-value (域-值)对设置到哈希表key中 HGETALL key 获取在哈希表中指定 key 的所有字段和值 HGET key field 获取存储在哈希表中指定字段的值。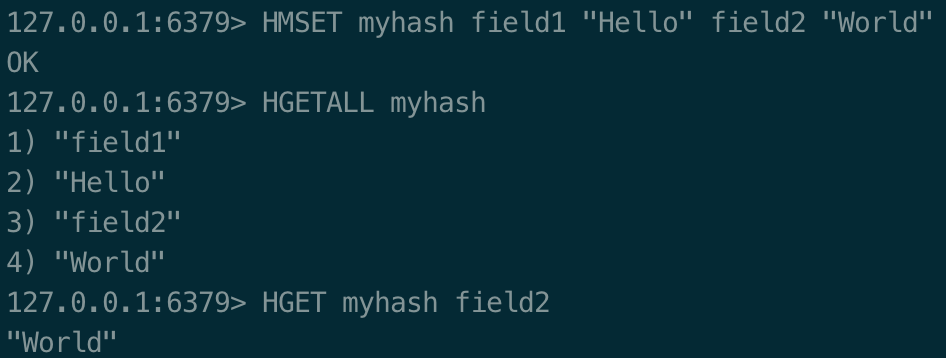
(3)list
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边) 一个列表最多可以包含 2 32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
列表的特点: 列表中的元素是有序的,可以通过索引下标来获取某个元素或者某个范围内的元素列表 列表中的元素是可以重复的
LPUSH key value1 [value2] 将一个或多个值插入到列表头部 LRANGE key start stop获取列表指定范围内的元素
返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。
其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。
你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
微博,某个大v的粉丝,就可以以list的格式放在redis里去缓存。 通过lrange命令,可以基于list实现简单的高性能分页,可以做类似微博那种下拉不断分页的功能。 简单队列,从list头部放入,从尾部取出。
127.0.0.1:6379> LPUSH runoobkey redis mongodb mysql (integer) 3 顺序是 mysql mongodb redis 127.0.0.1:6379> LRANGE runoobkey -2 -1 1) "mongodb" 2) "redis"(4)set
无序集合,自动去重 Redis 的 Set 是 String 类型的无序集合。 集合成员是唯一的,这就意味着集合中不能出现重复的数据。 Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。 可以基于set交集、并集、差集的操作,比如交集,可以把两个人的粉丝列表整一个交集,看看俩人的共同好友。
127.0.0.1:6379> SADD myset redis mongodb mysql (integer) 3 127.0.0.1:6379> SMEMBERS MYSET (empty list or set) 127.0.0.1:6379> SMEMBERS myset 1) "mongodb" 2) "redis" 3) "mysql"(5) sorted set
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
排序的set,去重但是可以排序,写进去的时候给一个分数,自动根据分数排序,最大的特点是有个分数可以自定义排序规则。 Redis中的SortedSet根据一个名为score的64位双精度浮点数的参数实现排序. 但是在实际应用中推荐将score当做64位长整型来使用. 原因很简单: long的取值范围要大于double.
排行榜:将每个用户以及其对应的什么分数写入进去,zadd board score username,接着zrevrange board 0 99,就可以获取排名前100的用户;zrank board username,可以看到用户在排行榜里的排名
ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数
ZRANGE key start stop [WITHSCORES]
Returns the specified range of elements in the sorted set stored at key. The elements are considered to be ordered from the lowest to the highest score. Lexicographical order is used for elements with equal score.
It is possible to pass the WITHSCORES option in order to return the scores of the elements together with the elements. The returned list will contain value1,score1,…,valueN,scoreN instead of value1,…,valueN.
If start is larger than the largest index in the sorted set, or start > stop, an empty list is returned. If stop is larger than the end of the sorted set Redis will treat it like it is the last element of the sorted set.
通过索引区间返回有序集合成指定区间内的成员
127.0.0.1:6379> ZADD myzset 1 "one" 2 "two" 3 "three" (integer) 3 127.0.0.1:6379> ZRANGE myzset 0 -1 1) "one" 2) "two" 3) "three" 127.0.0.1:6379> ZRANGE myzset -1 -2 (empty list or set) 127.0.0.1:6379> ZRANGE myzset 2,3 (error) ERR wrong number of arguments for 'zrange' command 127.0.0.1:6379> ZRANGE myzset 2 3 1) "three" 127.0.0.1:6379> zrange myzset -2 -1 1) "two" 2) "three" 127.0.0.1:6379> zrange myzset 0 1 withscores 1) "one" 2) "1" 3) "two" 4) "2" Zrank 返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。 127.0.0.1:6379> ZRANK myzset "one" (integer) 0
-
rabbitMQ高可用方案
普通模式
默认的集群模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。当rabbit01节点故障后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
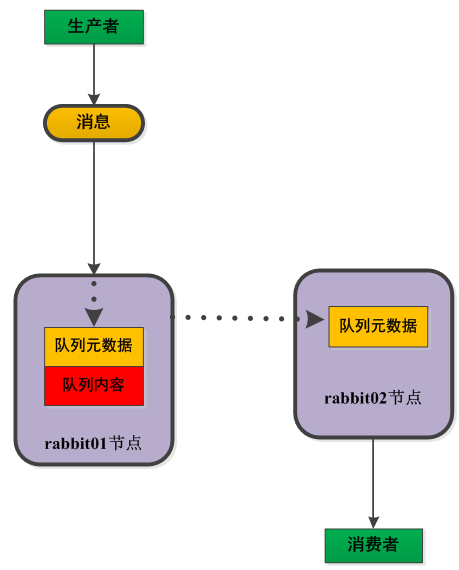
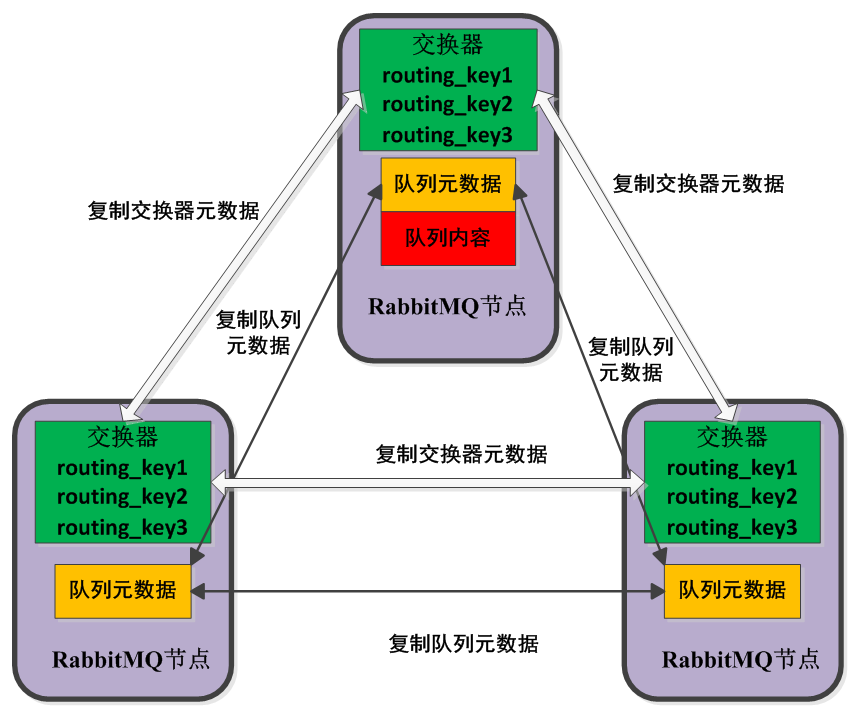
下面表示在集群配置下的不同节点创建队列的情况
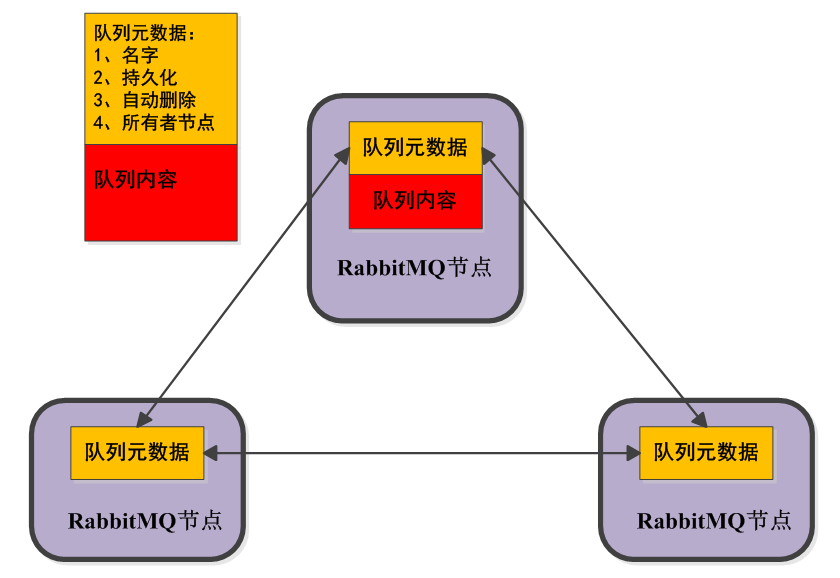
下图表示在集群配置下的不同节点创建交换器和队列的绑定的情况
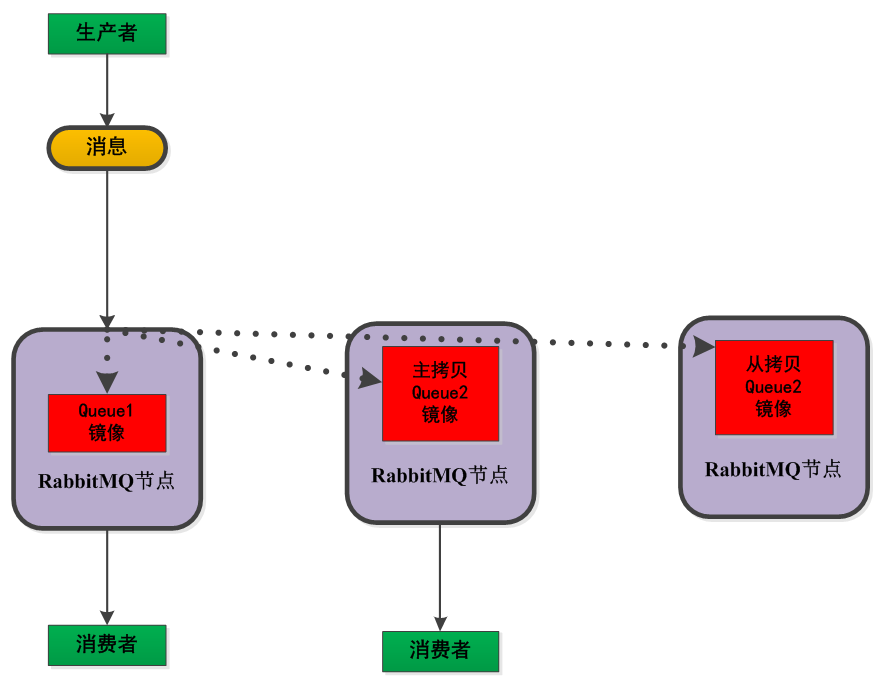
镜像模式
将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
-
亿级数据中判断数据重复
一、使用hashset去重
@Test public void hashMapTest() { long start = System.currentTimeMillis(); Set<Integer> hashset = new HashSet<>(SIZE); for (int i = 0; i < 10000000; i++) { hashset.add(i); } long end = System.currentTimeMillis(); System.out.println("执行时间:" + (end - start)); }将数据全部加载到内存,这种方式在内存有限的情况会出现OOM,比如设置JVM参数:
-Xms64m -Xmx64m -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError -XX:+UseParNewGC -XX:+UseConcMarkSweepGC将提示异常:
java.lang.OutOfMemoryError: Java heap space at java.util.HashMap.resize(HashMap.java:703) at java.util.HashMap.putVal(HashMap.java:628) at java.util.HashMap.put(HashMap.java:611) at java.util.HashSet.add(HashSet.java:219) at com.jep.leetcode.TestBloomFilter.hashMapTest(TestBloomFilter.java:25)查看GC日志:
{Heap before GC invocations=0 (full 0): par new generation total 19648K, used 4551K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000) eden space 17472K, 26% used [0x00000007bc000000, 0x00000007bc471e70, 0x00000007bd110000) from space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000) to space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000) concurrent mark-sweep generation total 43712K, used 0K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000) Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K class space used 495K, capacity 530K, committed 640K, reserved 1048576K Heap after GC invocations=1 (full 1): par new generation total 19648K, used 0K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000) eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000) from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000) to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000) concurrent mark-sweep generation total 43712K, used 959K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000) Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K class space used 495K, capacity 530K, committed 640K, reserved 1048576K } {Heap before GC invocations=1 (full 1): par new generation total 19648K, used 0K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000) eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000) from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000) to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000) concurrent mark-sweep generation total 43712K, used 959K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000) Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K class space used 495K, capacity 530K, committed 640K, reserved 1048576K Heap after GC invocations=2 (full 2): par new generation total 19648K, used 0K [0x00000007bc000000, 0x00000007bd550000, 0x00000007bd550000) eden space 17472K, 0% used [0x00000007bc000000, 0x00000007bc000000, 0x00000007bd110000) from space 2176K, 0% used [0x00000007bd330000, 0x00000007bd330000, 0x00000007bd550000) to space 2176K, 0% used [0x00000007bd110000, 0x00000007bd110000, 0x00000007bd330000) concurrent mark-sweep generation total 43712K, used 918K [0x00000007bd550000, 0x00000007c0000000, 0x00000007c0000000) Metaspace used 4188K, capacity 5098K, committed 5248K, reserved 1056768K class space used 495K, capacity 530K, committed 640K, reserved 1048576K }invocations=后的数字表示的是总的GC次数 full后的数字则是其中full GC的次数
二、布隆过滤器
前置知识
哈希函数:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。
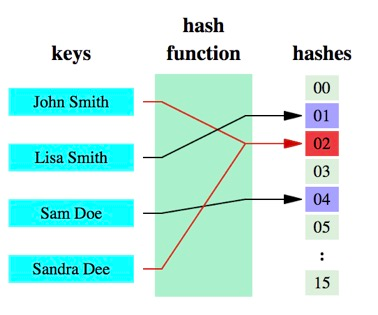
原理介绍
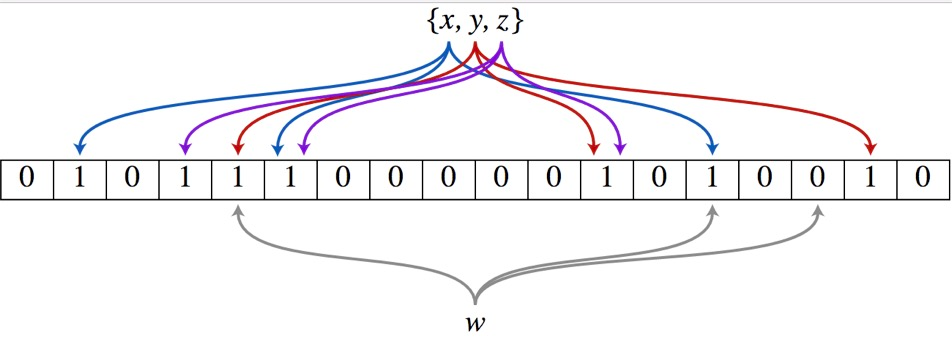 1、假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。
1、假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。2、对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
3、查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中(即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个数据最后定位到的位置是一模一样的,这点和 HashMap 类似)。
添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
-
flink安装及第一个示例
brew源在国外,因此采用静态安装方式:https://flink.apache.org/downloads.html下载最新包。
设置环境变量
FLINK_HOME=/Users/Ian/dev/flink-1.7.1 PATH=$FLINK_HOME/bin:$PATH
执行启动命令
start-cluster.sh Starting cluster. Starting standalonesession daemon on host jep.local. Starting taskexecutor daemon on host jep.local.进入管理页面:http://localhost:8081/#/overview
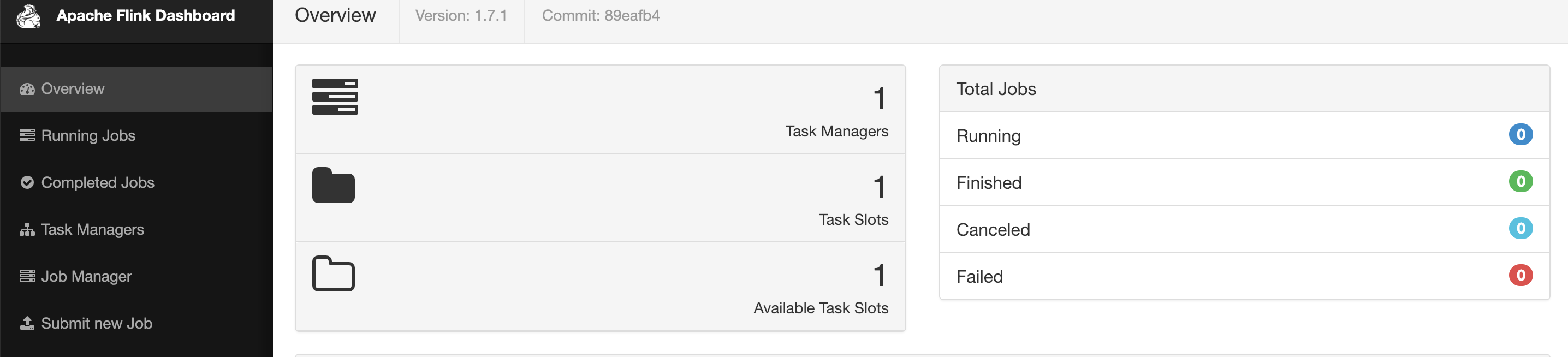
查看日志:
~/dev/flink-1.7.1/log tail flink-\*-standalonesession-\*.log新建flink工程
https://mvnrepository.com/artifact/org.apache.flink/flink-quickstart-java/1.7.0
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-quickstart-java</artifactId> <version>1.7.0</version> </dependency>在idea中新增archeType,按照以上的内容填写。 然后选择该archeType新建工程
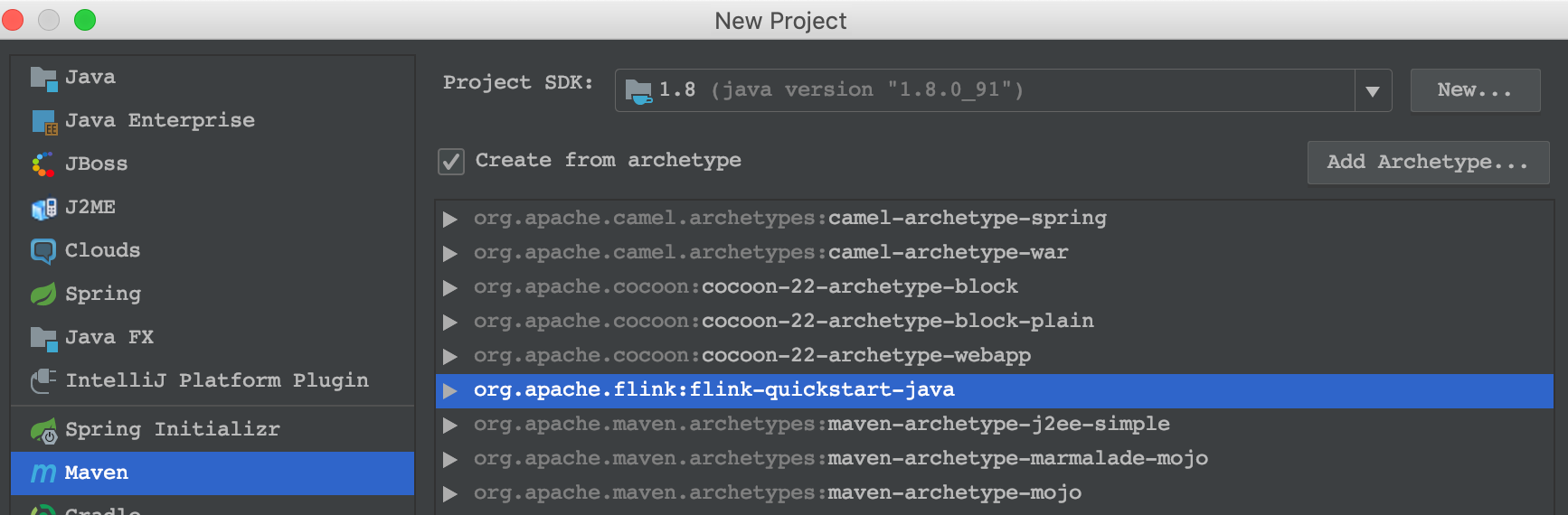
代码如下: ```java public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {